In today’s fast-evolving software landscape, staying updated with the latest tools, frameworks, and practices is both a challenge and an opportunity. One powerful way to stay on top is by using a Technology Radar — a curated, visual map that helps teams make smart technology decisions.
If you want to build software that lasts, you need a compass to guide you. Let’s explore what a technology radar is, why it matters, and how adopting one can transform your team’s approach to technology.
A technology radar is not a static list but a living document, regularly updated by tech leads and experts. It categorizes technologies across different domains:
Programming Languages
Frameworks & Libraries
DevOps Tools
Cloud Platforms
Testing & QA Tools
And more
Each tech is assigned to one of four rings:
Adopt: Mature, proven, recommended for immediate use.
Trial: Promising tech worth evaluating in projects.
Assess: Worth watching but not yet ready.
Hold: Technologies that have issues or are becoming obsolete.
This methodical approach brings clarity to choices, reduces risk, and encourages innovation responsibly.
Encourages Strategic Technology Adoption
With so many options, it’s tempting to jump on the latest trends. A radar prevents impulse decisions by grounding tech adoption in research and experience.
Facilitates Communication and Alignment
Developers, architects, and management get a shared language and framework for discussing tech. This helps break down silos and build consensus.
Improves Onboarding and Knowledge Sharing
New team members quickly grasp what’s recommended, what’s experimental, and what’s off-limits — reducing onboarding friction.
Supports Continuous Improvement
By reviewing the radar regularly, teams keep learning and adapting, staying relevant without chaos.
Inside the repository, you’ll find a directory for data (commonly src/data or similar) with files in YAML or JSON format describing your radar contents.
rings: -name: Adopt -name: Trial -name: Assess -name: Hold quadrants: -name: Languages & Frameworks -name: Tools -name: Platforms -name: Techniques items: -name: React ring: Adopt quadrant: Languages & Frameworks description: A popular JavaScript library for building user interfaces. -name: GraphQL ring: Trial quadrant: Tools description: A query language for APIs.
In an ever-shifting technology landscape, a Technology Radar acts as a vital compass for your software journey. By thoughtfully building, maintaining, and sharing your radar through a user-friendly website, you create a culture of strategic tech choices and continuous improvement.
If you want to stay ahead of the curve, start your own technology radar today — and empower your team with clarity and confidence.
RESTful APIs are a cornerstone of modern web development, allowing systems to communicate over HTTP using principles of Representational State Transfer (REST). RESTful APIs are designed to be scalable, stateless, and follow the HTTP protocol standards, making them highly effective for a wide range of applications.
In this blog, we'll explore the levels of RESTful APIs as defined by the Richardson Maturity Model, a framework that describes the stages of RESTful API maturity.
The Richardson Maturity Model breaks down RESTful APIs into four distinct levels, each building upon the previous one. These levels highlight the increasing adherence to REST principles.
At this level, APIs act as simple endpoints that accept requests and return responses. These APIs are typically not RESTful—they often use HTTP as a transport protocol rather than leveraging its full capabilities.
At the highest level, APIs provide Hypermedia as the Engine of Application State (HATEOAS). This means responses include links to related actions or resources, allowing clients to navigate the API dynamically.
Let's condiser the following business requirement we want to address:
Currently, local grocery stores must either visit large distribution companies or contact them individually to inquire about pricing, stock availability, and delivery schedules when placing orders. This process is time-consuming and inefficient for grocery managers.
To address this challenge, we propose developing a platform that enables managers to easily check prices, view stock levels, place orders, and track deliveries in one streamlined solution.
We aim to develop a RESTful API to provide access to product data, enabling consumers like microservices, mobile apps, and web applications to retrieve and display the information. This will allow end users, such as grocery store managers, to view, read, and stay informed about the available products on our platform.
Spring Data is a part of the broader Spring Framework ecosystem that simplifies data access in Java applications. It provides a set of powerful tools and abstractions that make it easier to interact with various data sources, such as relational databases, NoSQL databases, and more. Spring Data eliminates a lot of the boilerplate code typically involved in working with databases, enabling developers to focus on the business logic rather than the intricacies of data access.
In our case we will use PostgresSQL database, so let's first create a docker container for postgres and create also our database "grocery-marketplace":
An operational application that covers our use case is shared through Github at the end of this post.
tip
To start your own Spring Boot application, use Spring Initializr, an online tool that helps you quickly bootstrap your Spring project. You can specify the programming language, build tool, and dependencies.
There are several strategies you can use to create and manage tables in a PostgreSQL database, with Flyway being one of the most popular tools for handling database migrations in a structured way.
Let's see how to intstruments Flyway to create our tables and inserts sample data.
Flyway is a versioned migration tool that allows you to manage your database schema in a controlled and repeatable way.
It works by applying SQL-based migration scripts to your database.
Create SQL Migration Scripts
Flyway applies migrations sequentially based on versioned SQL scripts. These scripts should follow a naming convention like V1__Initial_schema.sql, V1__create_product_table.sql, etc.
Below a snippet of our V1__create_product_table.sql
-- Create tables for all related entities CREATETABLE category ( id INTPRIMARYKEY, name VARCHAR(100)NOTNULL ); -- Sample Data Insertion for related tables -- Insert categories INSERTINTO category (id, name)VALUES(1,'Electronics'); INSERTINTO category (id, name)VALUES(2,'Furniture'); INSERTINTO category (id, name)VALUES(3,'Clothing');
Flyway Configuration
You can configure Flyway in your application.yml (for Spring Boot) to point to your PostgreSQL database.
Running Migrations: When you start your Spring Boot application, Flyway will automatically detect and run any pending migrations in the db/migration directory, creating or modifying tables in the PostgreSQL database.
In JPA (Java Persistence API), an entity is a lightweight, persistent domain object that is mapped to a table in a relational database. It represents a record in the database and can be used to interact with that record through the application.
Below we define our first JPA Entity Category, which defines the category of product such as Electronics, Clothing, etc ...
@Entity dataclassCategory( @Id @GeneratedValue(strategy = GenerationType.SEQUENCE) val id: Int?=null, val name: String )
warning
Note that we didn't use the @Table annotation since the entity and table names are case-sensitive and match. If your table name differs, use @Table(name = "tablename").
a Spring Data Repository is an interface that allows you to interact with a data store (e.g., a relational database like MySQL, or a NoSQL database like MongoDB) without needing to write the implementation of the basic CRUD (Create, Read, Update, Delete) operations yourself.
In our case we will use the Spring Data JPA Repository which is a specific type of repository provided by the Spring Data project that simplifies the implementation of the Data Access Layer (DAL) for JPA-based (Java Persistence API) applications.
Below a snippet of our CategoryRepository:
As we may notice all we need to do is to implement an the generic interface JpaRepository that takes as first type an entity and a second type the identifier of the entity.
By default, Spring Data REST provides basic CRUD operations for the entities it exposes, including: GET, POST, PUT, and DELETE. In order to restrict operations to readonly one by implementing the following Spring interface:
Now, let's access our query api and explore the result:
GET /grocery/marketplace/query/api/v1 Host: http://localhost:8080
{ "_links":{ // a subset of the full response, other entities cutted to make this example shorter "products":{ "href":"http://localhost:8080/grocery/marketplace/query/api/v1/products{?page,size,sort*}", "templated":true }, "categories":{ "href":"http://localhost:8080/grocery/marketplace/query/api/v1/categories{?page,size,sort*}", "templated":true }, "profile":{ "href":"http://localhost:8080/grocery/marketplace/query/api/v1/profile" } } }
Above we have a Spring Data REST response uses HAL format, which provides links to related resources.
"products" and "categories": These are URLs for fetching product and category data, with templated parameters (page, size, sort) that allow for pagination and sorting.
"profile": A link to the API's profile, which provides metadata about the API.
These links allow clients to navigate the API easily and interact with related data without hardcoding URLs.
Understanding the levels of RESTful APIs helps developers create systems that are more robust, scalable, and easier to use. While many APIs remain at Levels 1 or 2, aiming for Level 3 ensures a fully RESTful experience that adheres to the principles of the web.
Which level does your API align with? Share your thoughts in the comments below!
In this phase, we begin by collecting requirements from a business perspective to ensure a thorough understanding of the objectives. Once these requirements are established, we then investigate how architectural patterns and software development methodologies can be utilized to construct the product effectively.
Currently, local grocery stores must either visit large distribution companies or contact them individually to inquire about pricing, stock availability, and delivery schedules when placing orders. This process is time-consuming and inefficient for grocery managers.
To address this challenge, we propose developing a platform that enables managers to easily check prices, view stock levels, place orders, and track deliveries in one streamlined solution.
To develop a system that effectively tackles the relevant challenges and provides significant value, it is imperative that every aspect of the system is designed with users in focus. This makes it vital to thoroughly understand their frustrations, motivations, and expectations regarding the new product we are creating
Grocery Manager
Profile: Typically has a bachelor's degree.
Frustrations: Running out of stock, lack of visibility over deliveries, price comparison is a time-consuming task.
Motivations: Save management time, focus on customer relationships and service quality, ensure stock levels are always adequate.
Architecture & Design
In the previous section, we presented a brief overview of the business domain, requirements, and one of the system's future users. At this stage, we need to make architectural and design decisions.
While the brainstorming outputs for this example are somewhat limited, we can easily envision various services, such as Order Service, Provider Service, Delivery Service, and Product Service. Now, suppose we want to develop all these services simultaneously, with different teams specializing in distinct technology stacks. It is essential that these services remain decoupled from one another, ensuring that a change in the design of one service does not affect the others.
Regarding deployment, we aim to deploy the Product Service before the others to deliver value as quickly as possible. This necessitates that the services be independently deployable and scalable.
By organizing our product around services, we can enhance fault tolerance. For example, if the Delivery Service is unavailable, users should still be able to access other services. For these reasons, we believe that a microservices architecture is the most suitable architectural style for this project.
Regarding deployment, we aim to deploy the Product Service before the others to deliver value as quickly as possible. This requires that services be independently deployable and scalable.
The complexity of the business domain, the rules, and the number of services (system components) lead us to consider Domain-Driven Design (DDD). So, what is DDD?
info
DDD, as described in the excellent book Domain-Driven Design by Eric Evans (Addison-Wesley Professional, 2003), is an approach to building complex software applications that is centered around developing an object-oriented domain model.
A domain model captures knowledge about a domain in a form that can be used to solve problems within that domain.
In traditional object-oriented design, a domain model is a collection of interconnected classes. For example:
Figure 1: Object Oriented Domain Model
With this design, operations such as loading or deleting an Order object encompass more than just the Order itself; they also involve related data, such as order items and delivery details. The absence of clear boundaries complicates updates, as business rules, imagine a business logic such as "minimum order amounts" must be enforced meticulously to preserve invariants
This is where DDD can help, by using Aggregates
An aggregate is a cluster of domain objects within a boundary that can be treated as a unit
Figure 2 shows a simplified version of the domain model aggregates. Designing domain model using the DDD Aggregate pattern recommand that aggregates match a set of rules: 1. Reference only the aggregate root 2. Inter-aggregate references must use primary keys 3. One transaction creates or updates one aggregate
Figure 2: Domain Model Aggregates Simplified
Implementation
Now that we have designed the domain model aggregates and the achitecture implementation view Microservices, let's dive into the architecture logical view Hexagonal Architecture , please refer to this post to learn about
Architecture Implementation view, Hexagonal option and why we adopt it
I'm going to use Kotlin as programming language and maven as a build tool
What about starting with writing a test scenario for our uese case using TDD (Test Driven Development), this approach help me immediately implement business logic,
in this case ensure no order will be created with quantity less than 20 unit.
@Test fun`should not place order with quantity lower than 20`(){ val productId: ProductId =ProductId(UUID.randomUUID()) val providerId: ProviderId =ProviderId(UUID.randomUUID()) val quantity: Int =16 val orderCreated = placeOrder.invoke(productId, providerId, quantity) Assertions.assertEquals(orderCreated.state, OrderState.PLACED) }
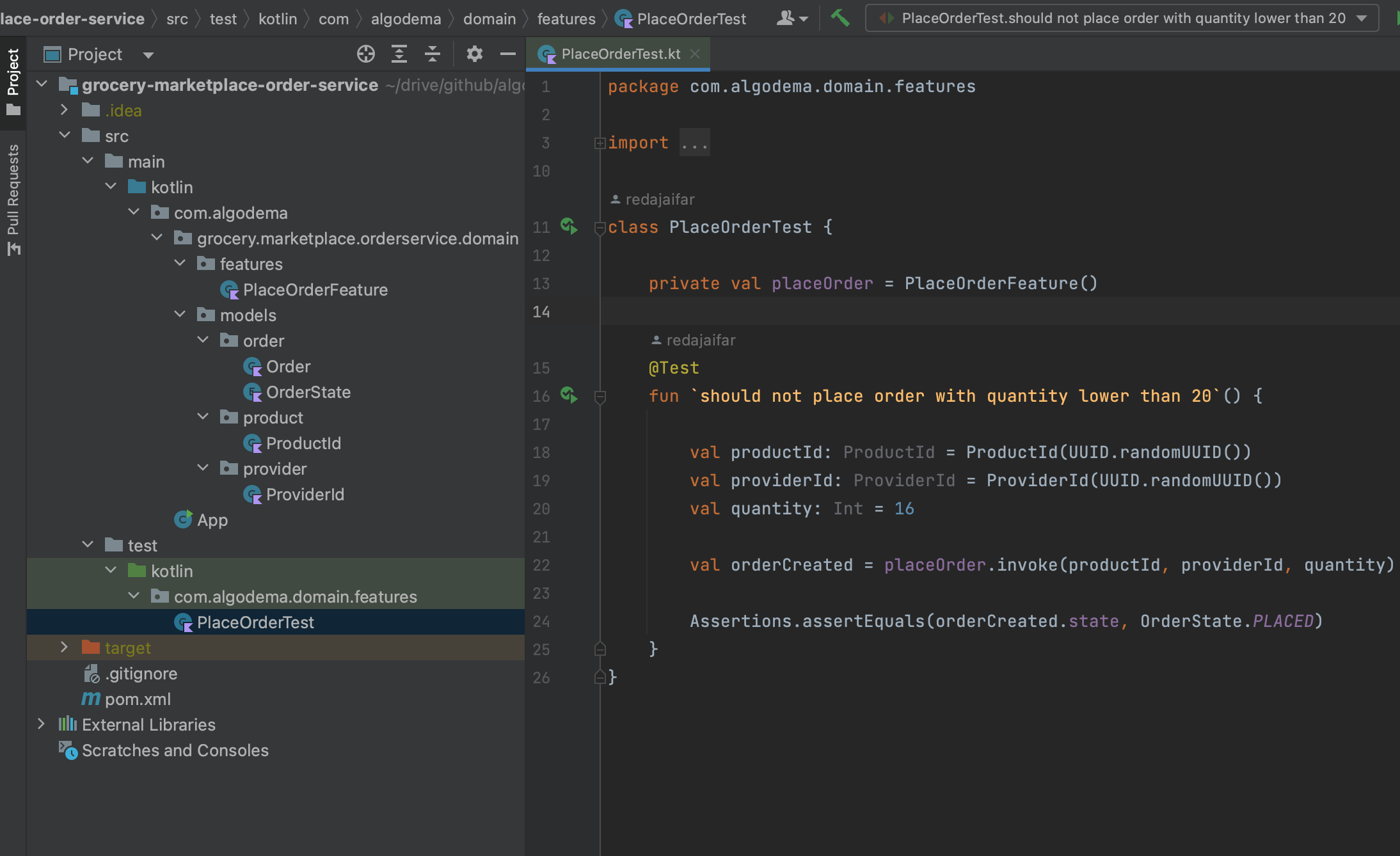
I started by creating "PlaceOrderFeatureTest" test class, then writing my first test as we see in the snippet above. If we look at the project structure in figure below:
note
Within the domain package, I created two sub-packages: features and models. The models sub-package includes representations of key domain entities, such as Order, OrderId, ProductId, and OrderState.
Meanwhile, the features sub-package contains feature-specific classes, with PlaceOrderFeature being the current implementation. It's important to note that in the models package, we organize classes according to their respective business domains.
The approach involves declaring instances of productId, providerId, and placeOrder prior to the existence of their respective classes. Subsequently, these classes are developed and organized into packages in accordance with the principles of hexagonal architecture,
which positions business logic at the core, as represented by the domain package.
We continue writing tests, they should be fixed and failed as we implement the business requirements in our place order feature.
Now that we created our first feature, we would like to expose it through a REST API endpoint, but also persist the created Order
in a storage, for the purpose of this tutorial, we will implement a in-memory persistence.
The hexagonal architecture defines ports and adapters as interfaces and implementations consequentially used to make the domain interacting and connecting with other components of the application such as (persistency, api, messaging, ...)
note
A port defines a set of operations that facilitate interaction between business logic and external systems.
In our Kotlin example, these ports are represented by Java/Kotlin interfaces.
An adapter manages requests from external sources or from the business logic itself by invoking external applications or services, such as databases or message brokers.
Both ports and adapters can be categorized as inbound or outbound to distinguish between requests directed toward the business logic and those initiated by it.
Ports destination packages
Ports will reside in the same root package as domain because they are integrated part of it. For our example: com.algodema.grocery.markeplace.domain.ports
As mentioned before, we separate them into 2 distinct sub packages:
Where adapters reside in the infrascture root package that we create to group all infrastcutures adapters such as:
REST API controllers classes
InMemory, Postgres or any other Repository implementations that serve to persist data.
External Systems integration such as SAPClient for example.
Let's create the follwing ports and adapters:
OrderRepository as an outbond port.
PlaceOrder as inbound port.
OrdersApi as inbound adapter that will use PlaceOrder port to expose the feature as REST API endpoint.
InMemoryOrderRepostory as an outbound adapter that will implement the OrderRepository port interface.
Below we created the InMemoryOrderRepository class that implements the domain port OrderRepository interface, Note also that we annotate this class
with the Spring framework @Repository in order to make it discoverable by Spring IoC container. Remember that we use Spring at the infrastcuture level without any coupling with the domain.
Next, we will introduce the Spring framework at the infrastructure layer to create a REST API. We rely on the Spring framework's dependency injection to make our component connections decoupled.
Using Dependency Injection, the place order feature will hold an instance of OrderRepository to save the created order, and at the infrastructure's API adapter, the REST Controller will hold instances of our features by dependency injection as well.
note
This is where Hexagonal Architecture shines. We can replace Spring by any other framework for exposing REST APIs or handling persistence without modifying the code within our domain.
This decoupling keeps the domain safe, adaptable, and maintainable, allowing us to change or add new business rules independently of the infrastructure.
For example, if we decide to switch to the Quarkus framework because it is better suited for cloud-native environments, the domain remains completely unaffected.
To enable Spring to identify our features for dependency injection, we will create a new root package designated as ddd. This package will encompass the necessary annotations:
As previously noted, we will be utilizing Spring Boot for this project. Therefore, it is essential to incorporate the Spring Boot and Spring Web dependencies into our project, as well as to include the Spring Boot Maven plugin within the Maven build plugins.
Let's create the OrdersApi in the infrastructure package under the sub package api, as follow:
package com.algodema.grocery.marketplace.orderservice.infrastructure.api import com.algodema.grocery.marketplace.orderservice.domain.features.PlaceOrder import com.algodema.grocery.marketplace.orderservice.domain.models.order.Order import com.algodema.grocery.marketplace.orderservice.domain.models.product.ProductId import com.algodema.grocery.marketplace.orderservice.domain.models.provider.ProviderId import org.springframework.web.bind.annotation.PostMapping import org.springframework.web.bind.annotation.RequestBody import org.springframework.web.bind.annotation.RequestMapping import org.springframework.web.bind.annotation.RestController @RestController @RequestMapping("/orders") classOrderServiceApi(privateval placeOrder: PlaceOrder){ @PostMapping funplaceOrder(@RequestBody placeOrderRequest: PlaceOrderRequest): Order { val productId: ProductId = ProductId.from(placeOrderRequest.productId) val providerId: ProviderId = ProviderId.from(placeOrderRequest.providerId) val quantity: Int = placeOrderRequest.quantity return placeOrder.invoke(productId, providerId, quantity) } }
We now need to configure Spring to recognize our annotated features, enabling them to be loaded into its bean container.
To achieve this, we will create a configuration class within a subpackage named config under the infrastructure package. Below is our configuration class:
You may have noticed the presence of the keyword "open" preceding the classes App, DomainInjectionConfig, and InMemoryOrderRepository. Here is the rationale behind this choice:
note
In Kotlin, classes are final by default, meaning they cannot be subclassed unless explicitly marked as open.
This is different from languages like Java, where classes are open for inheritance by default unless marked as final.
In Spring Boot (and Spring Framework in general), many of its features rely on proxy-based mechanisms. These mechanisms involve subclassing beans to apply aspects like transaction management, security, lazy initialization, and other cross-cutting concerns.
For these proxy-based features to work, Spring needs to be able to create subclasses of certain beans, which means the classes need to be open.
For the purpose of this exercice we decided to use the open modifier to make our classes annotated with Spring not final as we have few classes,
but for large application we can use the All-open compiler plugin instead of preceeding each classe required to be open with the open keyword.
Finally, let's run the application either using your IDE such as Intellij Idea or from command line using maven as follow:
mvn spring-boot:run
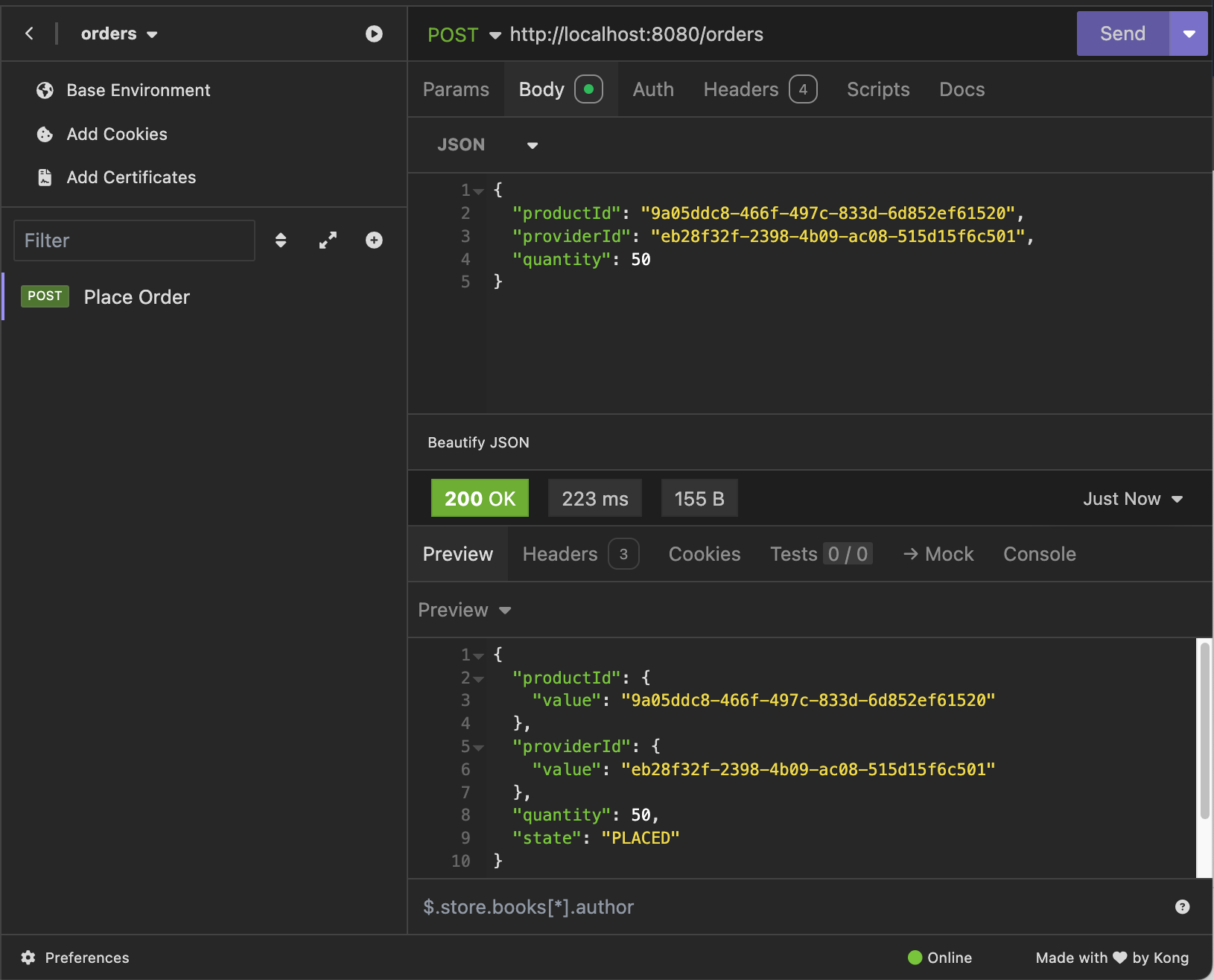
Below a screenshot of the place order request response overview:
This post has walked you through the entire process of building a fully functional Microservice, from design to implementation, using DDD and Hexagonal Architecture.
My goal was to share knowledge and experiences regarding the methodology, architecture, and patterns needed to create a maintainable, extensible, and deployable Microservice. However, delivering a production-ready product requires addressing more advanced aspects. Below is a non-exhaustive list of such considerations:
Api Errors Handling
Application security
Database persistency
Api documentation
Env variable config
Keep in mind that no single pattern, architectural style, or programming language suits all software product requirements. It's important to focus on understanding and defining the requirements, parameters, and challenges to make the most informed and effective decisions
Functions constitute a centric component in the recent software programs, the reason why we should care a lot about all
of
their aspects from naming, length, composition, arguments and error handling.
Yes "small" is the main rule a function should comply with, so it tell us what it does exactly because a function should
do one thing, do it well and only.
To keep the function also short, [if, else, while, etc ...] statements should be only one line, and probably this line
is function call:
Or the principle of "Doing one thing", the idea is not about writing function with single line of code, or one step but
writing it with the restriction to cover only one computation, see example below:
funvalidBookingRequest(bookingRequest: BookingRequest){ if(bookingRequest.from == bookingRequest.to){ throwInvalidBookingRequestException("departure and arrival stations are the same") }elseif(bookignRequest.stops >5){ throwInvalidBookingRequestException("more than 5 stops is not allowed") } }
We write code to be read, so writing functions in an order like a narrative text, if we have to put the functions of the
above
two examples, they should appear in the following order:
While switch statement can easily impact badly you clean code, The key issue with switch statements is that they often
lead to violations of the Single Responsibility Principle (SRP) and can make code harder to extend and maintain.
funcalculateWashCost(vehicle: Vehicle): Money { when(vehicle.type){ CAR ->calculateCarWashCost(vehicle) BUS ->calculateBusWashCost(vehicle) MOTOCYCLE ->calculateMotoCycleWashCost(vehicle) else->{ throwInvalidVehiculeType(vehicle.type) } } }
There many issues with this function above, first the function is large and each time new vehicle type will be added, it
will grow even more.
Second it violates the Single Responsibility Principle (SRP) because there is more one reason for it to change, but the
worst probem is there will be more functions
that will have the same structure:
CalculateParkingCost(vehicle: Vehicle): Money
CalculateCarbonTax(vehicle: Vehicle): Money
A solution proposed by Robert C.Martin is his book "Clean Code" is to hide the switch statement in an abstract factory,
and the factory will use the switch statement
to create the appropriate instances of the derivatives of Vehicle. And the various functions such as
CalculateParkingCost, CalculateCarbonTax will be dispatched polymorphic through the Vehicle interface.
Don't hesitate to make your function's name long if necessary in order to ensure a significant name.
When it comes to function argument the ideal number is 3, then comes one (monadic), followed closely by two (dyadic).
Three arguments (triadic) should be avoided where possible. The challenge with arguments resides in testing you can
imagine the difficulty of writing all
the test cases to ensure that all the various combinations of arguments work correctly.
Have you ever heard about "Flag Argument"? Flag argument is an argument of type boolean where the function do a thing
when it's true and another thing if it's false,
these arguments violates the Single Responsibility Principle (SRP).
The Command-Query Separation (CQS) principle states that a function should either perform an action (a command) or
return
data (a query), but not both. This makes the code more predictable, easier to test, and cleaner.
// Query function: returns whether the withdrawal can happen (no state modification) funcanWithdraw(balance: Int, amount: Int): Boolean { return amount <= balance } // Command function: performs withdrawal by returning the new balance (state modification, no return of query data) funwithdraw(balance: Int, amount: Int): Int { returnif(canWithdraw(balance, amount)){ balance - amount // Returns the updated balance }else{ balance // No changes if insufficient funds } } funmain(){ var balance =100 // Query if withdrawal is possible if(canWithdraw(balance,50)){ // Command: Update the balance by performing withdrawal balance =withdraw(balance,50) println("Withdrawal successful. New balance: $balance") }else{ println("Insufficient funds") } }
Let's admit that functions are fundamental components of our code, so it's crucial to invest time and effort into defining them properly, including their names, arguments, and statements.
Writing software is similar to any other form of writing—you begin by drafting your ideas, then refine them until they flow smoothly. Remember, we write code not just for execution, but also to be easily understood by others.
We, software engineers almost spent more time reading code than writing new lines, how many times do we complain about someone else's code? Many factors can give us an idea about
the quality of code and how much the writer cares about it. If you dislike reading bad code, you already made your first step toward writing good code if you care about
your heritage.
There are many good reasons to care about writing clean code, adding the artistic layer to your code is an inspiring reason for me to learn and apply the clean code rules and principles.
Clean code is what makes us professional programmers, someone with high-level ethics who cares about the present and the future of his code, he believes that lines of code
can live for long and can be enhanced by others with ease and passion. Like a book author what makes him happy is how readers enjoy turning the pages of his book one after the other without realizing the time elapsed.
Clean code makes us more than a programmer, it helps us develop a good vision of the software we are building, caring about its growth, evolutionary, and enhancement. Clean code makes us a thinker about
maintainability, design, and the ability of the software to cope with changes quickly and easily.
Code is written to live but also to change and evolve.
Yes, we programmers are authors, that said, we have readers, Indeed we are responsible for communicating well with readers. The next time we write a line of code, we'll remember
we are authors, writing for readers who will judge our effort.
As a programmer the first step of writing code is choosing names, for variables, functions, classes, packages and source code files.
While this seems easy and instinctive, choosing good names takes time but saves more than it takes.
Let's look at the following code snipped:
d = Date.now();
The name "d" above has nothing to reveal, even tough it is a date object, but we cannot know the intention of usage, either its start date or end date.
Note that even naming it startDate doesn't give it any sense, because we need to know as a reader what is the context of the start date.
Hers is a suggestion for this example:
Abbreviation Is one of the most common mistakes concerning variable naming, as a programmer can you guess what this variable name below means?
msg
Can you know that msg may mean "message" or "most scored goal"? Personally, I don't want to spend time exploring many lines before
or after this one to understand the context of this variable in case I need to make a change. The rule is to avoid any disinformation.
Another issue with naming is the number-series such as (variable1, variable2), consider the following function:
public static void duplicateString(char a1[], char a2[]){ ... }
is it not more readable if we use "source" and "destination" as the names of the two arguments? I think yes, it is.
Adding noise words is another problem that impacts the cleanness of the code, you may want to specify that a variable is
a String, so you name it: "emailContentString", Here the "String" is just redundant as is not part of the name but the type
which has nothing to do with the meaning of the variable.
As a programmer, there is a good chance that while we are writing code, our brain is pronouncing the text we type. when we cut the connection
between our brain and the activity of writing, we usually type variable names that could be difficult to pronounce, and the consequences
are multiple: other developers won't be able to retain them easily and these names will be demanding to discuss with the business analysts.
While English is the most used natural language used to write code, using other languages such as French or Italian, apply the same rules regarding
how easily the variables, functions, or classes names are pronounceable.
Each time I take over developing a new feature or fixing a bug that requires modifying a source code that not has been writing by me,
I start by searching some keywords that I got from the context of the domain system. For Example when I was asked to fix
a UI bug in a web application developed using ReactJS then I was trying to find the matching component in the source code, but it was not as
easy as expected and I spent 30 minutes before finding the component named with a number prefix: 1CounterComponent. This is why
choosing names that are straightforward to find is a very useful rule to follow.
Every programming language provides coding conventions regarding variables, functions, classes, and naming source code files. While
the naming took a good part of these conventions, they also cover indentation, comments, declaration order, etc ...
I don't hesitate to refer to these conventions. But during my modest experience, I came across some coding conventions
from specific programming languages applied to another one. This is strongly discouraged or prohibited by the teams themselves.
We write code to build software that will be solving a problem, For example: coding an application that computes taxes.
Trying to be a good programmer implies differentiating technical things from business-related ones. whenever you code
a technical concept don't try to use mainly a domain name, For example: declaring a variable that holds an instance of the
HTTP client could have the following name: httpClient, but if we try to include the business-related usage we can name it:
taxesRulesHttpClient as you can see in this case the domain doesn't bring any help instead is just making a technical
thing harder.
Writing clean code requires a piece of cultural knowledge and good descriptive, communication, and writing skills, we can develop
these skills by learning from communication experts either by reading books or taking courses on how to write, synthesis, and
order ideas. Also evolving on the natural language we use to code. For example, if we write code in English, it will be helpful
to learn more words, synonyms, sentences, etc...
So far I wanted to pay your attention to the importance of clean code, and how can impact the software's quality and maintenance,
We covered mainly the naming concept in this part. Other articles will follow to cover other aspects concerned by clean code.
Functional tests are one of these software testing approaches or test types such as (unit tests, integration tests, load tests, penetration tests, ...) all with one mission to test that the software is compliant whether with business specification, technical requirements or other quality and usability metrics. But functional tests focus on ensuring that the software functions behave as expected by the business specifications, these tests don't interact with source code such as unit tests, but mainly with the software features.
A functional test usually puts the system, the application or the software we want to test in an initial state where we provide the necessary elements to make the test executable such as storing a list of cars in the database, then we test the feature find a car for the period of (2nd march to 7th march), then we validate that the output matches the expected result.
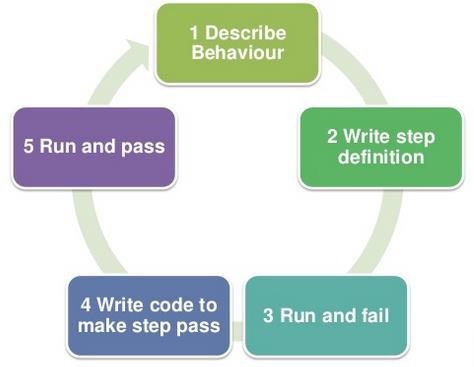
A common form that functional testing take is the Given-When-Then, this approach coming from the BDD (Behaviour Driven Development) defines the structure of many testing frameworks such as Cucumber that we will cover in our example later in this article.
The prime idea is to break down a scenario (test) into three sections:
Given: the given part defines the pre-conditions before challenging the system by executing or running a feature.
When: is do we want to do with the system, for example ( when I book a car)
Then: describes the expected result or output after the application or the software behaves in to respond to your action.
To simplify the idea, let's write an example for a rental car website using the Cucumber Tool (Framework):
Feature: User book a car
Scenario: User requests to book a car from 1st March to 7th March 2022
Given I select a car from the available cars for the period (1st March to 7th March 2022)
And I select GPS as an additional Option
And I select Full Insurance
When I book the car
Then I should receive a confirmation
BDD combines the best practices of Test Driven Development TDD, Domain-driven Development (DDD), and Object Oriented Programming (OOPs)
For an agile team, scoping a feature is a very important task, as the stakeholders are talking about the business requirements, the development team is more interested in the technical challenges, Here comes the BDD to provide a common language that allows efficient communication and feedback and then a perfect specification, development vision, and feature delivery.
BDD closes the gap between the business and the technical people by:
Encouraging collaboration across roles to build a shared understanding of the problem to be solved.
Working in a rapid and small iteration to promote the feedback and optimize the value delivery.
Producing documentation that is automatically checked against the software behavior.
There is a good chance that you're agile at your organization so you already plan your work in small increments of value like User Stories. In this case, BDD will help you to deliver your promises of agile on time. BDD does not replaces your processes but enhances them.
Let's focus on the word Behaviour so functional testing of behavior testing is these tests your write to check your system or the software you're building how behaves. Functional testing can also be called behavior testing.
To illustrate all these abstract notions explained briefly in this article, let's write a small application and its behavior tests using Kotlin programming language and Cucumber
Kotlin is a JVM programming language, like Java, Scala, or Groovy
Cucumber is a testing tool that supports Behavior Driven Development
Gherkin is a business readable language that helps you to describe business behavior without going into details of implementation
We will need the following to build this example:
Java SE (Java 9 and higher are not yet supported by Cucumber)
git clone https://github.com/reda-jaifar/hands-on-kotlin.git cd sportair
Open the project in IntelliJ IDEA:
File -> Open… -> (Select the pom.xml)
Select Open as Project
Verify Cucumber installation
mvn test
Now our environment is ready, let's write some scenarios for the following application:
SportAir is an application that indicates whether we
can exercise outside or not based on the weather.
In Cucumber, an example is called a scenario. Scenarios are defined in .feature files, which are stored in the directory (or a subdirectory).
Create an empty file called src/test/resources/sportair/can_we_exercice_outtside.feature with the following content:
Feature: Can we exercise outside?
Everybody wants to know if we can exercise in the air
Scenario: The weather is not convenient for exercising outside
Given The temperature is 42 celsius
When I ask whether I can exercise outside
Then I should be told "Nope"
if you're using Intellij Idea Cucumber Plugin, you should see the keyword colored, below the meaning of each:
Feature: is a keyword that should be followed by the feature name, a good practice is to use the name of the file. The line that follows is a description that will be ignored by Cucumber execution parser.
NB: We use a feature by file
Scenario: defines the name of a scenario, we can have as many scenarios as expected by a feature.
Given, When, Then: are the steps of the scenario. Refers to the definition above.
mvn test
The output should be something like the following: Given The temperature is 42 # StepDefs.The temperature is(int) When I ask whether I can exercise outside # StepDefs.I ask whether I can exercise outside() Then I should be told nope # StepDefs.I should be told(String) Scenario: The weather is convenient for exercising outside # sportair/can_we_exercice_outside.feature:9 Given The temperature is 24 # StepDefs.The temperature is(int) When I ask whether I can exercise outside # StepDefs.I ask whether I can exercise outside() Then I should be told of course # StepDefs.I should be told(String) 2 Scenarios (2 passed) 6 Steps (6 passed) 0m0.181s Tests run: 2, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.403 sec Results : Tests run: 2, Failures: 0, Errors: 0, Skipped: 0
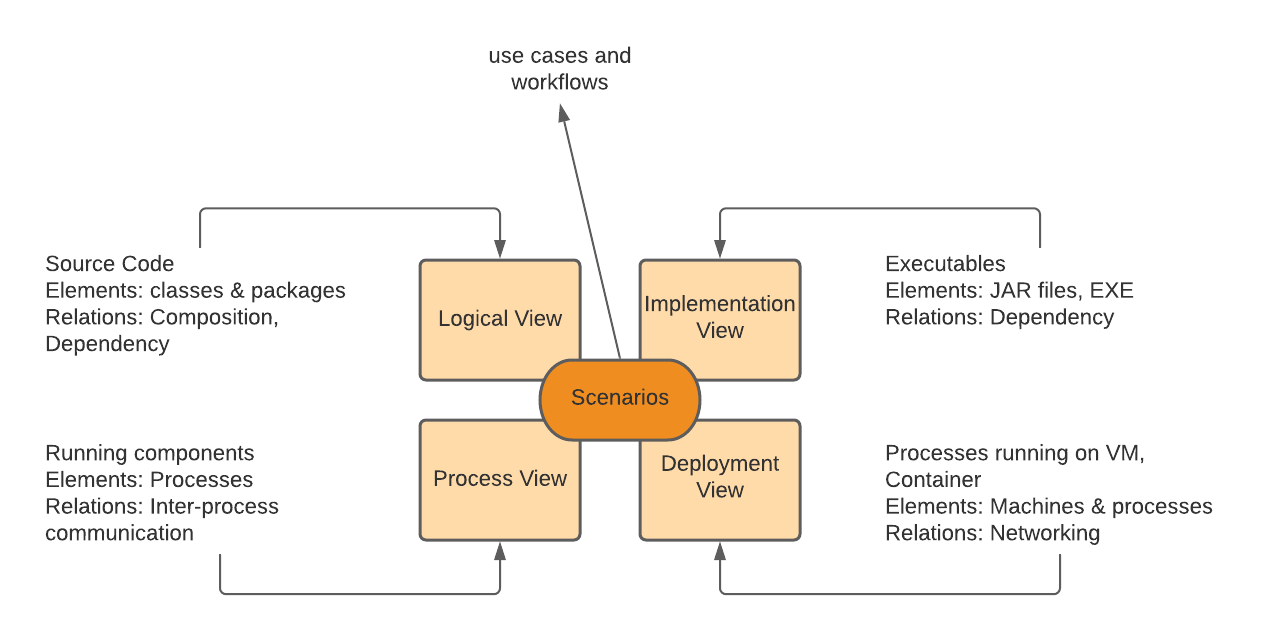
The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests
Includes the result of the build process that can be run or deployed such as a Java JAR or Node.js Package. These artifacts interact
with each other in the form of a composition or dependency relationship.
Let's extract the definition of monolithic architecture from an example. Imagine you are invited to develop an enterprise application for
managing music concerts ticketing, One of the requirements is to access the system from the browser and a mobile native application. SO the application
will handle HTTP requests, execute a function and access a database to persist the data. One of the design options we may have
is to create different components each one is responsible for a specific business logic (event subscription, payments, ticket editing ...). if we choose to develop with
the java programming language and the spring framework, we'll have one application with many modules interconnected and coupled to accomplish
the job. But what about the deployment? what type of build output will generate and how to deploy it into a production environment.
The answer is we will generate a single Java WAR file.
The monolithic representation of our example application (Music Event Application) where we can distinguish bounded functions of the system but all in one artifact
This is what monolithic architecture is about to define the output of your source code as one piece that you can easily:
Deploy (push or put into the production environment, or any other environment such as development or staging)
Scale (run multiple instances of the application in response to increasing traffic)
Debug (in case of non-normal behavior of the system you can explore the logs, check the config, and so on to find the error, all these things are on the same process)
Question: Now the system is up and running, but a new feature is required which needs to update the payment provider within our application, how can we achieve that?
Answer: we have to update the source code, re-build the whole application, think of a deployment strategy to ensure service continuity of our application.
In the context of our monolithic application, many drawbacks are rising while changing a small piece of the system:
Even though the change concern only one part of the system, this one becomes indivisible and decoupled, the build and deploy process is slower because all the source code should be re-build to generate the new artifact (Java WAR file)
The whole system is developed with one stack which limits the on-boarding of other developers with different backgrounds
Less re-usability of the components.
Increasing the artifact (build output) volume.
Reliability as one bug in the ticket editing component can cause the whole system to shut down.
In the next section, we discuss the alternative and how microservices address many of the drawbacks of monolithic and bring new added value but also some very challenging points to handle.
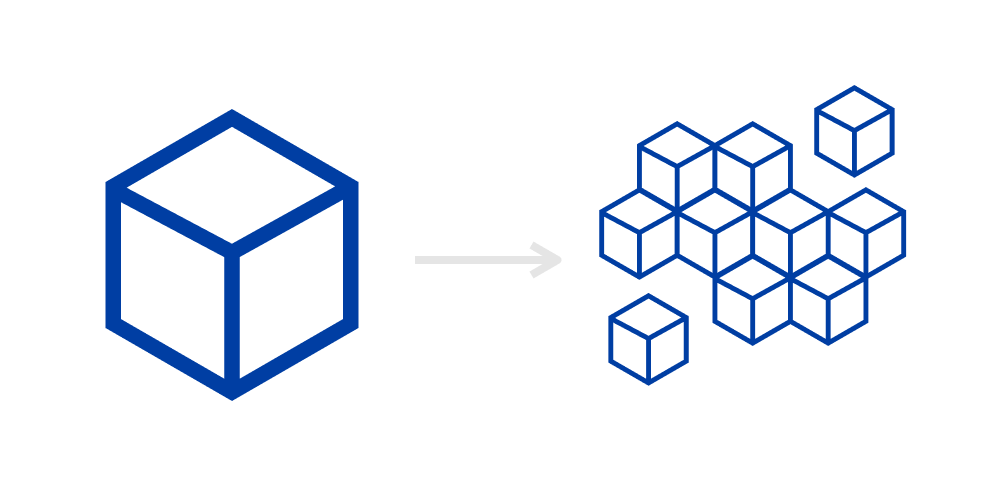
Microservices architecture style organizes the application as a set of loosely coupled, independently deployable services, Together these services deliver the functional and business
features of the system we want to build. Let's continue with our Music Event Application example and try in the above illustration to define its microservices architecture:
The Microservices representation of our example application (Music Event Application) where 3 services communicate through HTTP using REST
As we can observe in the illustration each service run in an independent process and also could have its database(recommended), Notice also how these services communicate
to each other, in this example, I suggest using the REST API through HTTP, but this is not the only communication option we can have, there are more such as messaging using a message broker.
Let's tackle with further detail the microservices inter-communications in a dedicated article, so far and the rest of this document we will use REST as a reference.
As the word service is a most recurrent when we explore the microservice architecture, Here is a definition:
A service is an independent deployable application or software component that provides a set of functionalities accessible
through an API. Service has its own logical architecture, Hexagonal architecture may fit many use-cases, In addition
a service can be developed with its specific technology stack that may differ from other services' technology stacks in a microservices architecture
What is loosely coupled Services and why they should?
Two services are loosely coupled if changes in the design, implementation, or behavior in one won't cause change in others. In a Microservices architecture, the coupling will happen when
a change in one enforces an almost immediate change to one or more microservices that collaborate with it directly or indirectly.
While designing Microservices architecture, to make the services the less coupling possible, consider the following points:
the data storage is a microservice implementation detail that should be hidden from its clients (usually other microservices).
If Microservice A needs to access data of Microservice B, B should provide an API that A will use to consume the needed data
By definition, microservices do not share codebase, but we may want to avoid redundancy by sharing dependency libraries and
end up needing to update frequently in response to that libraries' client's change requests. So shared code should be as minimum as possible.
A good practice that may seem strange at glance is to duplicate code so each service has its copy, so we need to update
the library to match Service A requirements, Service B remains un-impacted
In a Microservice architecture, services cooperate to accomplish the job, so they need to communicate either asynchronously or
synchronously where the service caller expects a timely response from the callee service might even block while it waits. To address the potential
response latency, we can integrate a caching mechanism or implement the circuit breaker pattern to avoid cascading failures. These two options
could help remediate the system quickly, but for the long term, the best alternative is switching to asynchronous communication
by using a messaging broker like Apache Kafka, So services can cooperate by publishing and consuming messages.
When it comes to designing the next-generation software, relying on a strong and reliable architecture helps a lot, In
recent decades, much great software conquered the market and is serving millions of users while scaling up and down to reduce
cost and energy or respond to an increasing number of requests. Microservices Architecture is part of other practices
and engineering designs behind thanks to its benefits, below is a non-exhaustive list:
Independent development: microservices can be developed in isolation to accomplish a defined functionality
Independent deployment: microservices can be deployed individually and independently in any environment (cloud, on-premise, managed infrastructure)
Fault isolation: if one service fails, the system remains up and only the functionality provided by that stopped microservice will be impacted
Technology stack: different programming languages, frameworks, and technologies can be used to build the same software, usually a SaaS
Individually scaling: each service can scale as per need, is not necessarily to scale the whole system as is the case of monolithic based application
Despite the number of advantages Microservices Architecture is bringing, choosing it over Monolithic Architecture relies upon
on the context, the application domain (banking, delivery, e-commerce, ...) and scope (either is a lightweight application or
a complex evolving application), your organization software engineering capabilities and culture.
The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests
This is my first architecture style I've discovered 10 years ago thanks to my java enterprise application course teacher, Ths idea
consist of organizing the elements of an application into layers. Those elements could be java classes grouped by the responsibility type
they manage and respect the rule that each layer should depend only on the layer below it, Another version also tolerate that a layer can
depends on the any of the layers below it.
Even though we can apply this architecture style to any of the 4 model view we've seen above, It is most likely to be used in the logical view
as follows:
Presentation layer: groups classes & interfaces that handle the UI interactions, Such as desktop application UI that handles user interactions like Click, Press, etc...
Business logic layer: contains classes where we implement the business logic of the system. For example classes that calculate the shortest route for delivering merchandise from stock house to customer.
Persistence layer: contains interfaces and classes that interact with database or file system. For example classes that communicate with a MySQL database.
In the above figure, we illustrate the 3 tier architecture for a java application, classes of the same layer are grouped using packages.Note that architecture is beyond
any programming language, so for example in case of a C# application we group classes in namespaces instead of packages for java.
The years go by and the software development community began to recognize some drawbacks of N Tier architecture, below we list some of them:
Single Presentation Layer: With the evolution of the web and mobile applications, many systems provide the same functions, For example a desktop application
for logistics providing the feature of calculating the shortest route and cost of a delivery, While the business logic remains the same,
the interactions with the system are evolving with mobile and web users.
Single Persistence Layer: Modern systems needs to interact with many and/or different storage systems rather than one database.
Layer dependencies: As the business logic depends on the persistence one, we are prevented from testing the business logic in an isolation.
These disadvantages lead to an alternative architecture style we present next.
This architecture style organizes the logical view in a way that puts the business logic at the center. In contrast to the layered
architecture that has a presentation layer, we have here one or more inbound adapters that handle requests from the outside by invoking
the business logic. The same applied to the persistence layer, the application has or more outbound adapters that are invoked by the business logic and invoke external applications.
The main characteristic of this architecture style is that the business logic doesn't depend on these adapters, instead they depend on it.
The Business logic has one or more ports.A port defines a set of operations and is how the business logic interacts with
what's outside it. For example in java these ports are a Java Interface. we distinguish inbound and outbound ports. An inbound port is an API exposed by
the business logic, which enables it to be invoked by external applications, for example a REST API.An outbound port is how the business
logic invokes external systems like Database Access Repositories.
Like the ports there are inbound and outbound adapters. An inbound adapter handles requests from the outside world
by invoking an inbound port. For example in the case of a Java Web Application using Spring framework, An inbound
adapter is a Rest Controller that will invoke inbound port exposed by the business logic.
An outbound adapter implements an outbound port and handles requests from the business logic by invoking an external
application or service.An example of an outbound adapter is an Event Publisher to Kafka or any other Event streaming system.
The Figure above shows an example of the hexagonal architecture where the business logic has one or more adapters to communicate with external systems
Let me remind you that decoupling the business logic from the presentation and data access is the important benefit
of the hexagonal architecture style. This is very useful also when it comes to testing as you can use TDD
easily as you can test your business logic in an isolation.It also defines new model for the modern applications where the
business logic can be invoked by multiple adapters each one of them invokes an external system.
The Hexagonal Architecture style is well fit to define the architecture of each service in a microservice architecture.
Both the layered and hexagonal architectures are a set of constraints and rules on how elements within the logical
view are connected and how they communicate.
The software architecture of a computing system is the set of structures needed to reason about the system, which
comprise software elements, relations among them, and properties of both.by SEI
We can decrypt the above definition as structuring a system as a whole recessed block into parts connected, complementary and modular.
The more these parts are decoupled and can work independently, and communicate to each other effectively the more our architecture
will fill its mission to ensure a maintainable, extensible and homogeneous system.
The 4+1 view model of software architecture
Like a building, there are different plans and maps that can describe different the different perspectives of that building,
we have the electrical, plumbing, structural and others. This is exactly how the 4+1 view model defines software architecture
in the paper published by Phillip Krutchen
The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests
Each of the four views has a well-defined purpose as detailed below:
It consists of the source code written by developers, in the context of an oriented programming language like Java, the elements are
classes and packages, in addition to relationships between them such as inheritance, association, and composition...
Includes the result of the build process that can be run or deployed such as a Java JAR or Node.js Package. These interact with each
other in the form or a composition or dependency relationship.
Refer to the process holding and running either in virtual machines or containers like docker, relations between them is called
inter-process communication.
Represents the map of the physical or virtual machines where the system is executed and running, also describes the communication
at level through the network. For example this view can be a VPC with all the routing configuration inside this network and between it and the internet.
Why an application architecture is relevant?
An application come to life with the purpose of solving a problem, to do so it needs to fulfill two types of requirements, Functional requirements
that defines what the application should do, Previously defined in the form of specifications, with the agile edge we define them as user stories,
use cases, or events. we can start coding immediately and produce an application that respond to these requirements without thinking about architecture.
But when it come to develop a reliable, maintainable and extensible system, Architecture is our core activity because it helps us
answer questions regarding how the system behaves with millions of users at the same time, security threats and delivery time.
Architecture meets quality requirements.
Architecture Styles
I found the definition given by David Garlan and Mary Shaw in their publication titled An Introduction to Software Architecture
an amazing reference to understand the concept of architecture styles and how it can be view in the field of computing systems.
An architectural style, then, defines a family of such systems in terms of a
pattern of structural organization. More specifically, an architectural style
determines the vocabulary of components and connectors that can be used in
instances of that style, together with a set of constraints on how they can be
combined. These can include topological constraints on architectural
descriptions (e.g., no cycles). Other constraints—say, having to do with
execution semantics—might also be part of the style definition.
Follow are the questions shared by these two pioneers in the discipline of software architecture, answering these questions
will remarkably help define the architecture that fit for the system we're building:
Given this framework, we can understand what a style is by answering the
following questions: What is the structural pattern,the components,
connectors, and constraints? What is the underlying computational model?
What are the essential invariants of the style? What are some common
examples of its use? What are the advantages and disadvantages of using that
style? What are some common specializations?
in the next part, let's explore some of the most known architecture styles
Logical View
Nowadays the processes used to create software have been considerably evolved from manual and human interaction to test,
build and deploy an application to a fully automated process relying on new practices and tools that help teams to
deliver an update to production in few minutes or even seconds.
If your organization or team still using the old methods and have the willingness to take a step toward these useful
and helpful DevOps practices, there are some notions to consider while taking the way.









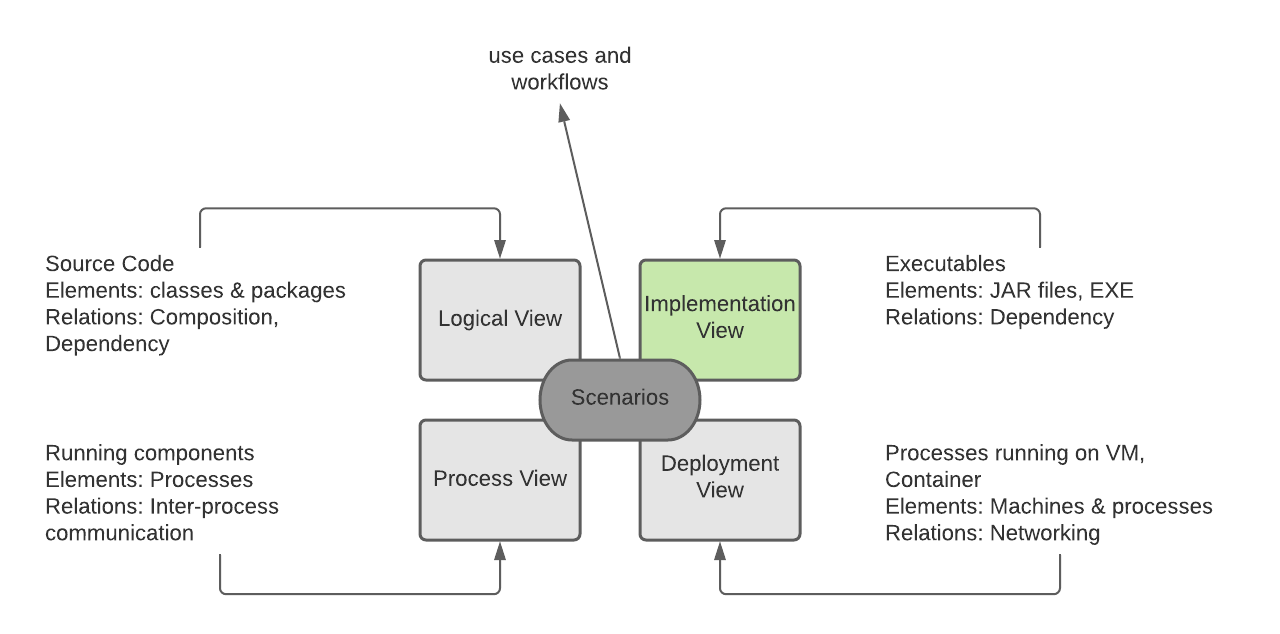 The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests
The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests
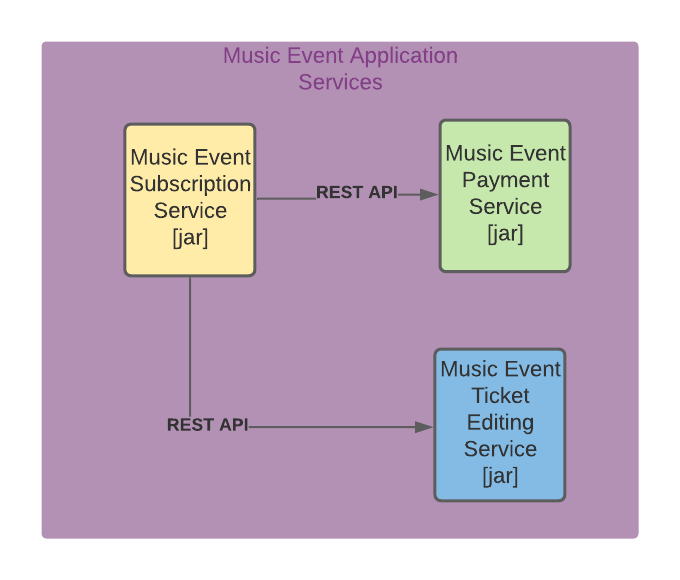 The Microservices representation of our example application (Music Event Application) where 3 services communicate through HTTP using REST
The Microservices representation of our example application (Music Event Application) where 3 services communicate through HTTP using REST
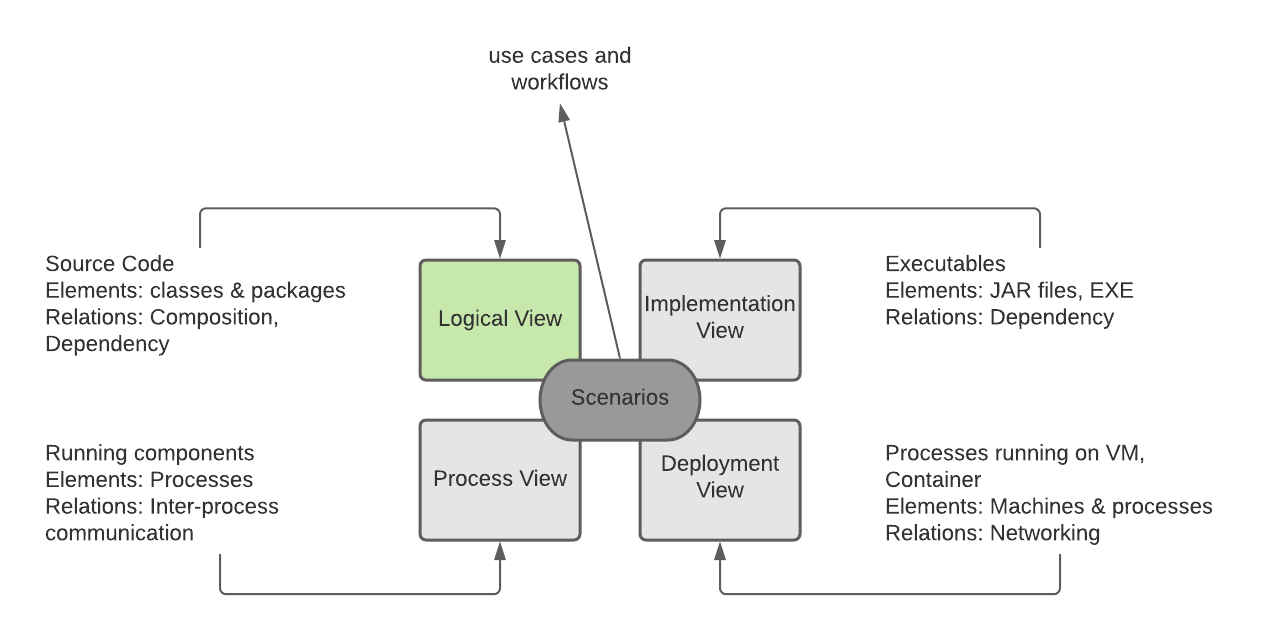 The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests
The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests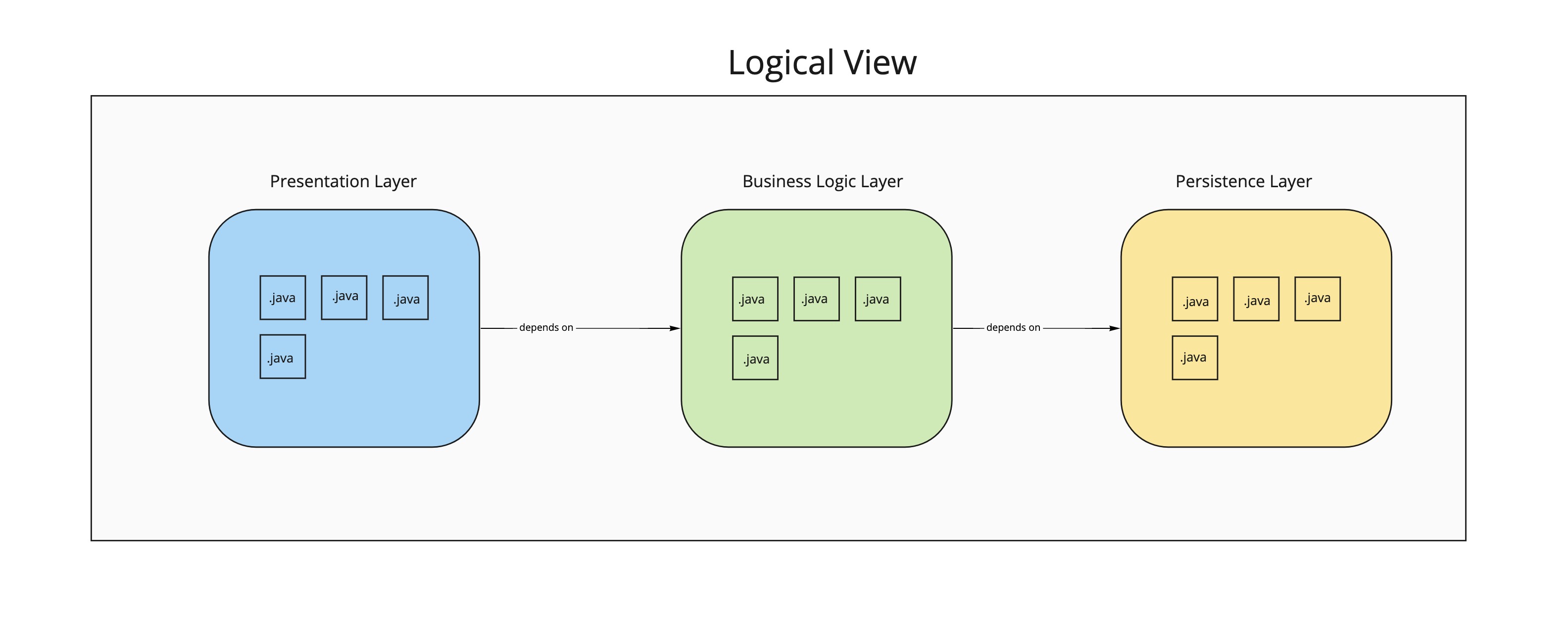 In the above figure, we illustrate the 3 tier architecture for a java application, classes of the same layer are grouped using packages.Note that architecture is beyond
any programming language, so for example in case of a C# application we group classes in namespaces instead of packages for java.
In the above figure, we illustrate the 3 tier architecture for a java application, classes of the same layer are grouped using packages.Note that architecture is beyond
any programming language, so for example in case of a C# application we group classes in namespaces instead of packages for java.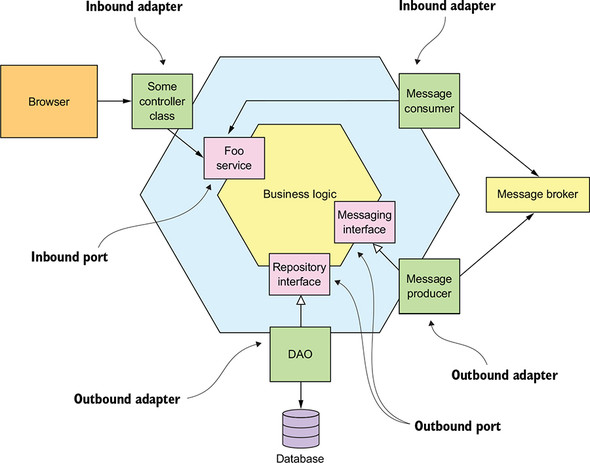

 The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests
The 4+1 view model describes an application’s architecture using four views, along with scenarios that show how the elements within each view collaborate to handle requests